【回復】AWS東京リージョンで障害発生 いろんなサイトが😢(マイネ王にも影響が)
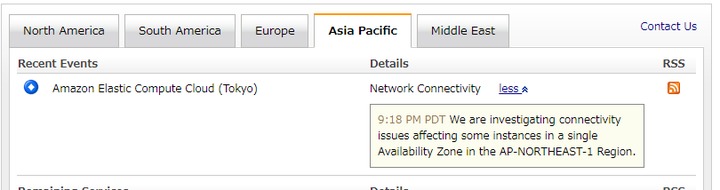
Amazon Web Services東京リージョンで障害が発生。
https://status.aws.amazon.com/
色んなサイトがアクセス不能になっている模様。
このマイネ王もAWS東京リージョンで動いてますが、挙動がおそーい。
解説は、こちらが詳しいです。
現在発生しているAWSの障害について – 株式会社サーバーワークス
https://www.serverworks.co.jp/news/20190823_aws_news.html
---
原因について

空調システムが故障→オーバーヒート状態に→機器がシャットダウン!
AWS Service Health Dashboard - Aug 23, 2019 PDT
https://status.aws.amazon.com/
やっぱり東京の夏は機械にも暑いのね #ちがう
--- 追加
AWSより最終報告が出ております。
ぜひご覧ください。
Summary of the Amazon EC2 Issues in the Asia Pacific (Tokyo) Region (AP-NORTHEAST-1)
https://aws.amazon.com/jp/message/56489/
41 件のコメント
コメントするには、ログインまたはメンバー登録(無料)が必要です。


https://www.synapz.jp/
そういや、以前、某大手企業の新品サーバーが(クレーン車から)落ちて、とてつもない話になった事を聞いた事があるなあ…。
関係してますか?
固定回線光
や
ワイモバイル
に切り替えてもマイネ王のみ
文のコメントだけも10秒以上かかります。
google 検索や他サイトは早いです。
マイネ王のみです。
こういうレベルのトラブルって、個人的にはほとんど異常気象に巻き込まれているのと変わらない気がします。どうしろと。w
結局は、いつものSmoozではなくSafariで送ることができました。
マイネ王がつかってる「とりもちアド」というシステムが、非常に遅いように見受けられます。
それに影響されて、マイネ王全体で遅い場面がおきてるようです。
とりもちは間違いなくAWSで運用されております。
送信に10程度かかってます。
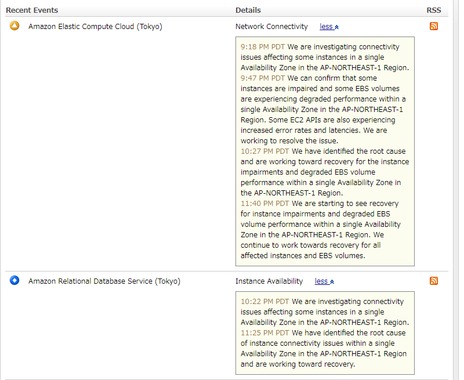
今回の大本の原因はすでに判明しているようです。復旧作業に期待しましょう。
アイドリッシュセブンも障害あるたらしいけど、ここまで世間に浸透してるAWSって本当にすごいね!
シナプスさん、ほんとうにできるチームなんだなー
マイネ王自体には影響ないんだもんな。
>>あんちゃんがやってるサイト、S3とCloudfront使ってるけど大丈夫だった!
それはあんちゃんがデキるお人だからだな!
そしたら全部設定考えるからよろしく!
画像がアップ出来無いですね(^_^;) 16:24
だいぶ収束してきたようなので、もう少し待てばいけるかも
グルグル回ってます。
停止して再起動するとミュート完了してます。
ほぼ、全滅です。確かにまだフリーズしますね。
我が家もadブロックつかってなんとか読めてる状況です。
NHKニュースです。
このコメントも上手く出来るといいのですけど?
っ⑩
とりもち(マイネ王で使ってる広告)ってどれなんだろ・・・。
>>とりもち(マイネ王で使ってる広告)ってどれなんだろ・・・。ここが”とりもち”エリアです。

サーバの温度が上がりすぎたことが原因だそうです。
なるほど、そのへん・・・ですか。そういえば、なんか邪魔だし、既に削除されている掲示板とかも表示されるし、ここのリンクから見ないな~って排除した様な…。
Amazonが使っているサーバーって純然な Open Compute Project準拠じゃなくてそこへ手を加えた特注品なので、代替の設備をどこへ持っていくかなどもすぐには振替が難しかったものと考えますけど。
AZ(Available Zone)の切り替えなり AZ内での移動を考慮した場合、
・AZ間切り替え→確か RDS(Relational Database Service)で DBの引き継ぎがそのままできないはず
・AZ内→基本は AZ内の範囲が「近隣のファシリティ(データセンター建屋)」に限定
だったはずなので。AWS Innovateなどのオンラインセミナーでもその辺りはそれとなく解説されてます。
かといって RDSを Region跨ぎするのは unsupportなので、何らかの形で RDBをレプリケーション→可能な限り同期するところまで持っていって仮復旧、などを考えないとならないでしょうね→サービス事業者側。
AWS特有の設計を十分考慮しないとこういう時に巻き添え食ってサービス影響が出てしまうんで、色々大変だと思いますけど早く復旧すれば良いとは思います。
追伸:
まあ、AWS東京リージョンの新拠点は先般、場所が割れてしまいました
し、基本 AWS側ではデータセンターの場所を非公開としてるので、
あそこはもう使えないんだろうなあ、などと思ってしまいます。
あそこもそこそこラック数収容できる場所だったはずなんですが。
(先般火災があった唐木田の建屋)

なんかサマーウォーズのシーンを思いました…
ばあちゃんの熱暴走、絶対阻止!!優先 ٩(ˊωˋ*)وしました
https://aws.amazon.com/jp/message/56489/
この度の事象発生時、異なるアベイラビリティゾーンの EC2 インスタンスや EBS ボリュームへの影響はございませんでした。
複数のアベイラビリティゾーンでアプリケーションを稼働させていたお客様は、事象発生中も可用性を確保できている状況でした。
--- 引用おわり
AWSが一番言いいたいのは、ここです。
「あぁん? 最初から言ってるよな? ちゃんと設計しろよ。」ですね。
> AWSが一番言いいたいのは、ここです。
> 「あぁん? 最初から言ってるよな? ちゃんと設計しろよ。」ですね。
私も余り意識していなかったのですが、AWSの RDSを使用する場合、どうも「Auroraを使わないと Multi-AZでのデータレプリケーションに制限が出る」らしく.....。
大抵商用サービスで使っていらっしゃる方々は Oracleなり PostgreSQLやらで、Auroraでの設計を行っているところがまだ多くない、というのもあるんだと思います。
DBの扱いがクラウドサービスでは一番面倒だったりしますので、ここで設計ミスしていた事例が多いなら見直しを行うのが良いのでしょうね。
※個人的には「クラウドでは DBを非同期レプリケーション→コミット
するまで若干時差を置くのが良いのかもしれない」なんて考えて
みたりしましたが。
でもそれだとサービスにおけるリアルタイム性が確保できないので
実は結構悩ましいというジレンマもあります。
→やっぱり RDBは別ストレージで DiretConnect使うとか考えるべき
なんだろうか?など(苦笑)
(もしくは RDBだけ Azure SQLに振ってしまうとか:))